
【开源软件】最好的开源软件-2022-第28名 EleutherAI
GPT-NeoX-20B是一个新的200亿参数的自然语言处理模型,由早期GPT-J的发行商EleutherAI创建,这是一个60亿参数的模型。与OpenAI的GPT-3相比,这些模型可能看起来很小,GPT-3有1750亿个参数,但它们使用LAMBADA、Winogrande、Hellaswag和其他数据集取得了强大的基准测试结果。你可以测试GPT-J的句子完成,并执行更高级的NLP任务,如翻译和分类。
EleutherAI推动开源如此强大的模型的背后是什么?该项目的创始人之一Conor Leahy解释道,“我们必须把人工智能视为思维与我们不同的奇怪外星人。”目标是让尽可能多的研究人员能够使用这项技术,这样我们就可以学会如何控制它。
——Isaac Sacolik
【数据保护】数据匿名的自定义NLP方法
消除真实世界私人数据识别的实用方法
随着互联网服务的普及,人们对互联网隐私的渴望不断增长。近年来,诸如GDPR等不同的法律开始发挥作用,这些法律规范了服务收集私人信息的方式。这引起了每家公司对隐私方面的关注,并增加了对处理和匿名私人数据的投资。
我在微软商业软件工程(CSE)团队的工作是与微软最具战略意义的客户合作。我们共同开发人工智能、大规模数据、物联网等领域的新工作负载。在与这些客户接触的同时,我们意识到,PII(个人身份信息)问题是许多希望在本地或云中扩展其解决方案集的公司反复出现的话题和障碍。
因此,我们决定为任何希望解决数据隐私问题的人创建Presidio,这是一项免费的生产准备开源服务。
Presidio允许任何用户在结构化和非结构化数据上创建标准和透明的匿名PII实体流程。为此,它公开了一组预定义的PII识别器(用于名称、信用卡号和电话号码等常见实体),以及用新逻辑扩展它的工具,以识别更具体的PII实体。在这篇博客文章中,我们将重点讨论如何利用自然语言处理来识别不同类型的私人实体。
【LLM 】7个基本的NLP模型,为ML应用程序赋能
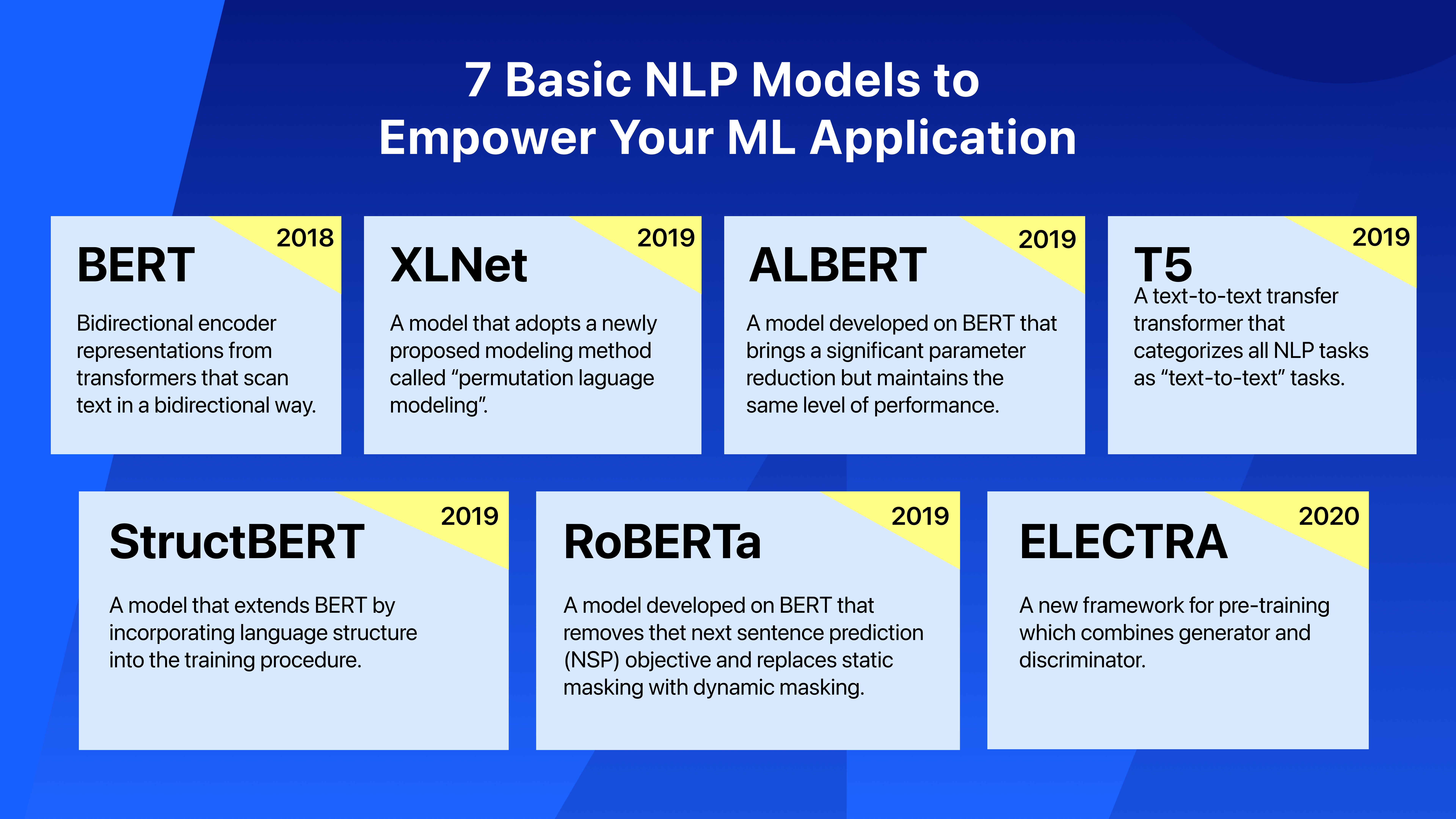
在上一篇文章中,我们已经解释了什么是NLP及其在现实世界中的应用。在这篇文章中,我们将继续介绍NLP应用程序中使用的一些主要深度学习模型。
【LLM】人工智能驱动的医学知识:罕见疾病护理的革命性变革
[编者按]:这是杰克·西蒙的客串帖子,他最近参加了威廉姆斯学院的黑客马拉松。他构建了一个由LangChain驱动的聊天机器人,重点关注阑尾癌症,旨在让有需要的人更容易获得专业知识。如果你有兴趣为另一种罕见的情况构建聊天机器人,请联系jms9@williams.edu.
我们之所以强调这一点,是因为我们认为这是问答系统的一个极好且不受重视的用例。虽然底层技术可能与其他问答应用程序类似,但我们发现这种用例对社会的影响特别大。
上周,我参加了威廉姆斯学院的一场黑客马拉松,在那里我建立了一个聊天机器人,它改变了我们获取罕见疾病信息的方式。通过结合文献综述、临床试验数据和学术论文,我创建了一个由LangChain驱动的聊天机器人,它可以提供有关一种特殊罕见疾病——阑尾癌症的宝贵信息。
虽然这个演示侧重于一种罕见的疾病,但我计划通过添加尽可能多的罕见疾病信息来扩展聊天机器人的知识库。最终愿景是创建一个人工智能驱动的应用程序,为患者和医疗保健专业人员提供可靠的信息来源。
【OpenAI】我如何使用OpenAI将公司的文档转化为可搜索数据库
以及如何对您的文档进行同样的处理
在过去的六个月里,我一直在一个初创公司Voxel51工作,该公司是开源计算机视觉工具包FiftyOne的创始人。作为一名机器学习工程师和开发人员,我的工作是倾听我们的开源社区,并为他们带来他们需要的东西——新功能、集成、教程、研讨会,你能想到的。
几周前,我们在FiftyOne中添加了对矢量搜索引擎和文本相似性查询的原生支持,这样用户就可以通过简单的自然语言查询在他们的(通常是海量的,包含数百万或数千万个样本)数据集中找到最相关的图像。
这让我们陷入了一个奇怪的境地:现在,使用开源FiftyOne的人可以通过自然语言查询轻松搜索数据集,但使用我们的文档仍然需要传统的关键字搜索。
我们有很多文档,这些文档有其优点和缺点。作为一名用户,我有时会发现,考虑到文档的数量,准确地找到我想要的内容需要比我想要的更多的时间。
【DetectGPT】斯坦福大学的DetectGPT采用基于曲率的LLM生成文本检测方法
ChatGPT能够在几秒钟内就任何主题生成连贯全面的文章,这使它成为改变游戏规则的信息资源,也是教育工作者的克星。OpenAI的对话式大型语言模型在发布后的几周内积累了数百万每日用户,但也被美国、澳大利亚、法国和印度的学区禁止。
虽然强大的大型语言模型(LLM),如ChatGPT(OpenAI,2022)、PaLM(Chowdhery et al.,2022)和GPT-3(Brown et al.,2020),有无数有益的应用,但它们也可以用来在家庭作业中作弊,或写令人信服但不准确的新闻文章。此外,他们经常产生虚假信息。因此,区分机器从人类书写的文本中生成的任务在许多领域变得至关重要。但随着LLM输出变得越来越流畅和人性化,这项任务变得越来越困难。
斯坦福大学的一个研究团队在新论文《DetectGPT:使用概率曲率的零样本机器生成文本检测》中解决了这个问题,提出了DetectGPS,一种新的零样本机器生成文本的检测方法,使用概率曲率来预测候选通道是否由特定LLM生成。

该团队将其研究的主要贡献总结如下:
【NLP】用于自然语言处理 (NLP) 的出色深度学习
Table of Contents
【NLP】最棒的中文医学NLP公开资源整理
中文医学NLP公开资源整理:术语集/语料库/词向量/预训练模型/知识图谱/命名实体识别/QA/信息抽取/etc
【自然语言处理】很棒的中文NLP资料
A curated list of resources for NLP (Natural Language Processing) for Chinese
中文自然语言处理相关资料
图片来自复旦大学邱锡鹏教授
