
category

For the past 6 months, I’ve been working on LLM-powered applications using GPT and other AI-as-a-Service providers. Along the way, I produced a set of illustrations to help visualize and explain some general architectural concepts.
Below is the first batch, I’m hoping to add more later on.
Table of Contents
1. Basic Prompt
2. Dynamic Prompt
3. Prompt Chaining
4. Question-answering without hallucinations (RAG)
5. Vector database
6. Chat Prompt
7. Chat Conversation
8. Compressing long discussions
1. Basic Prompt
The most fundamental LLM concept:
- you send a piece of text (called prompt) to the model,
- and it responds with another piece of text (often called completion).
It’s essential to remember that, fundamentally, LLMs are only trying the most statistically probable next words to complete your prompt. Hence the term “completion”. This is key to understanding and leveraging some behaviors or these models.
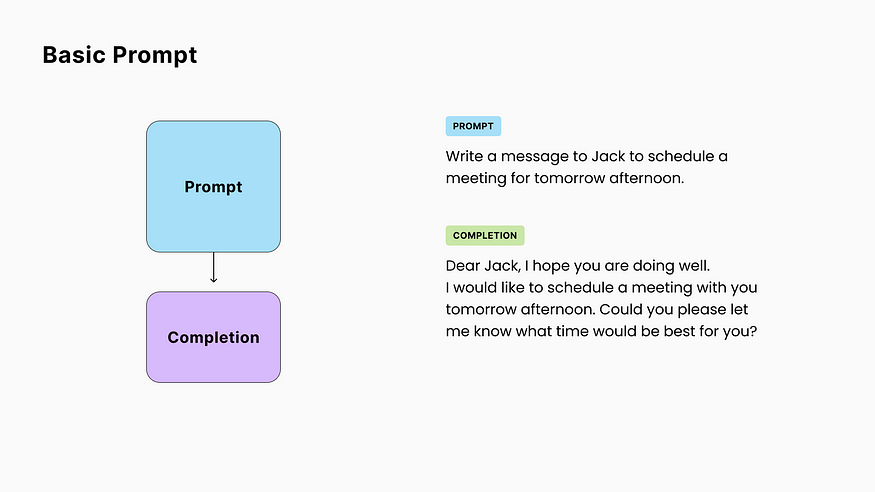
2. Dynamic Prompt
A common practice in LLM apps is to create a “prompt template” and dynamically replace parts of it with the user data before sending the final prompt to the LLM.
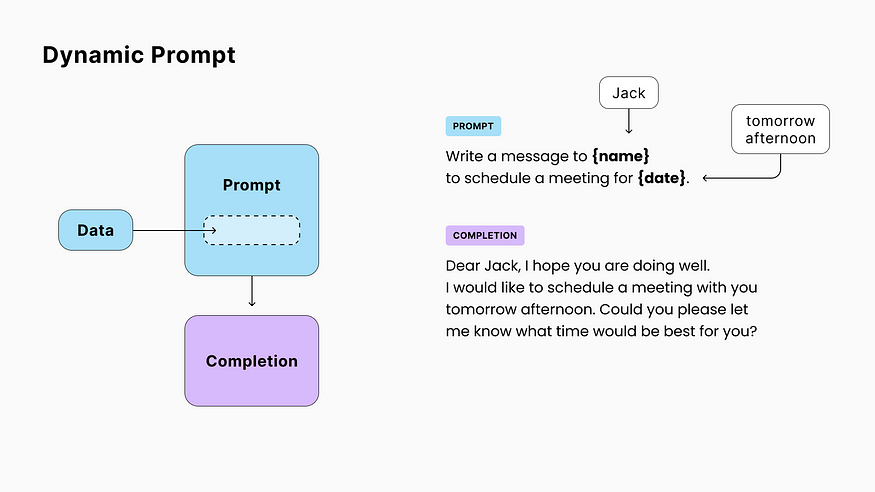
3. Prompt Chaining
In some cases, a single LLM call may not be enough. Maybe because the task is complex or the full response wouldn’t fit in the context window (maximum tokens/words the model can read and write per request).
That’s when you can use prompt chaining: incorporating the response from the first call into the prompt of the next one.
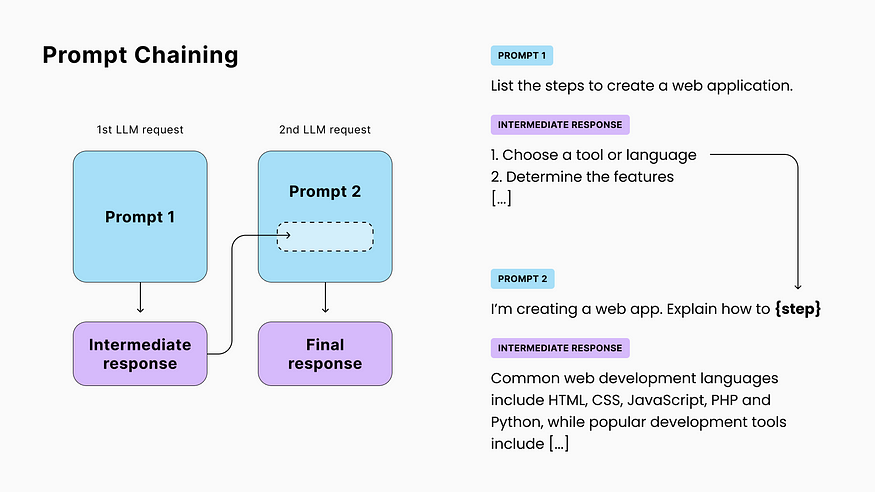
4. Question-answering without hallucinations (RAG)
Because LLMs answer questions instinctively, they sometimes come up with incorrect answers called “hallucinations”. This is a problem for fact-related use cases like customer support.
However, while LLMs are not good with facts, they’re excellent at data extraction and rephrasing. The solution to mitigate hallucinations is to provide the model with multiple resources and ask it to either find the answer with those resources or respond with “I don’t know”.
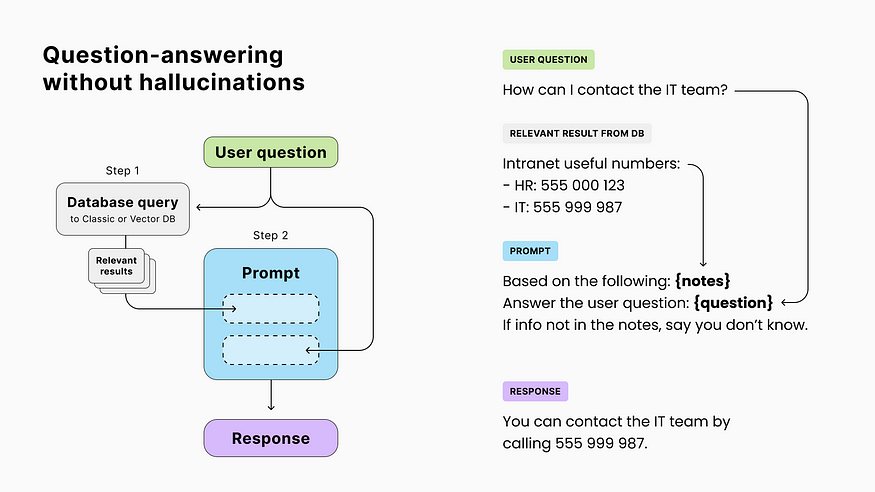
The technique of retrieving resources to augment the prompt and improve the output is known as RAG (Retrieval-Augmented Generation).
5. Vector database
Retrieving relevant resources for the use case above can be challenging with traditional databases and word-to-word matching. The same word can have different meanings in different contexts.
In a Vector Database, items (words, sentences, or full documents) are indexed by a sequence of numbers representing their meaning.
These numbers are coordinates in a multi-dimension space (often with 1500+ dimensions). Some of these dimensions can capture concepts such as “natural ←→ synthetic”, “positive ←→ negative”, “colorful ←→ bland”, or “round ←→ pointy”.
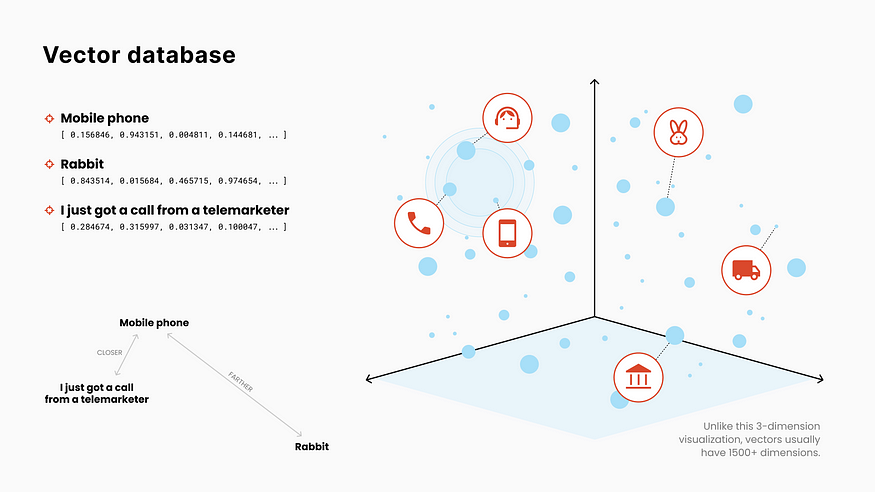
Then, using geometry, it's easy to calculate the distance between the meaning of two items and find the closest matches based on our input.
6. Chat Prompt
Introduced by OpenAI with their popular GPT-3.5-turbo model, chat prompts use a slightly different format representing a discussion, where the completion would be the next message in the sequence.
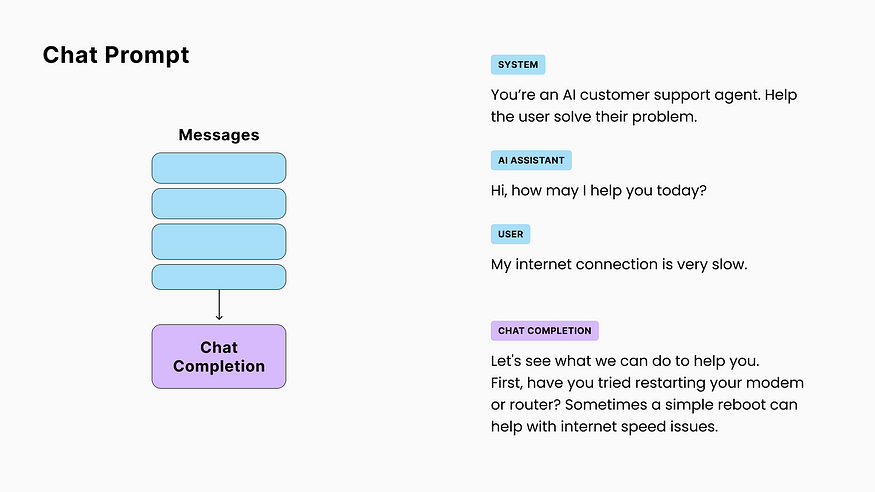
☝ It’s important to note that, while GPT’s chat API expects a sequence of role/message and are finetuned (optimized) with this specific structure, a chat prompt is equivalent to a text prompt formatted as follows:
SYSTEM: You're an AI customer support agent... AI: Hi, how may I help you today? USER: My internet connection is very slow AI:
☝ Also, because OpenAI’s chat models are more performant and cheaper than their non-chat ones, we often use chat models for tasks that don’t involve discussion. You can place your instruction in the first system message and get your response in the first AI message.
For all the examples below, you can use chat prompts and chat-formated text prompts interchangeably.
7. Chat Conversation
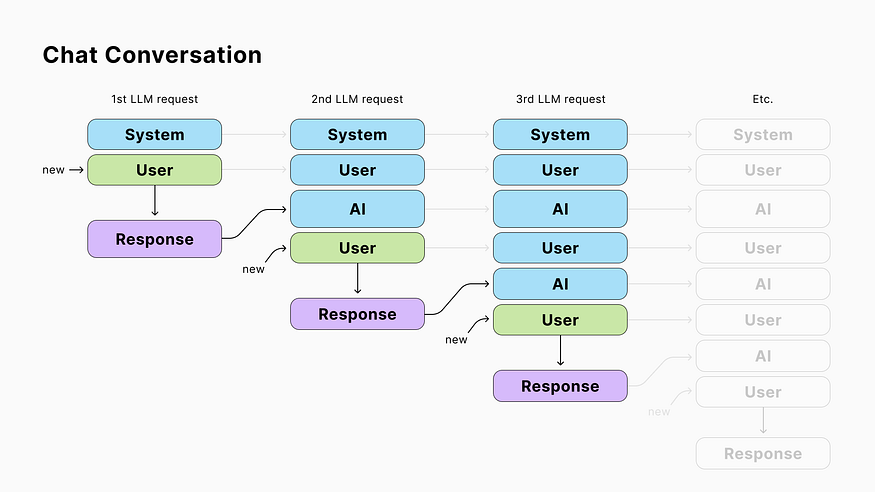
LLMs are stateless, meaning they don’t store data from previous calls and treat each request as unique. However, when you chat with an AI it needs to be aware of what was said before your last question.
To address this, you can store the chat history in your app and include it with each request.
8. Compressing long discussions
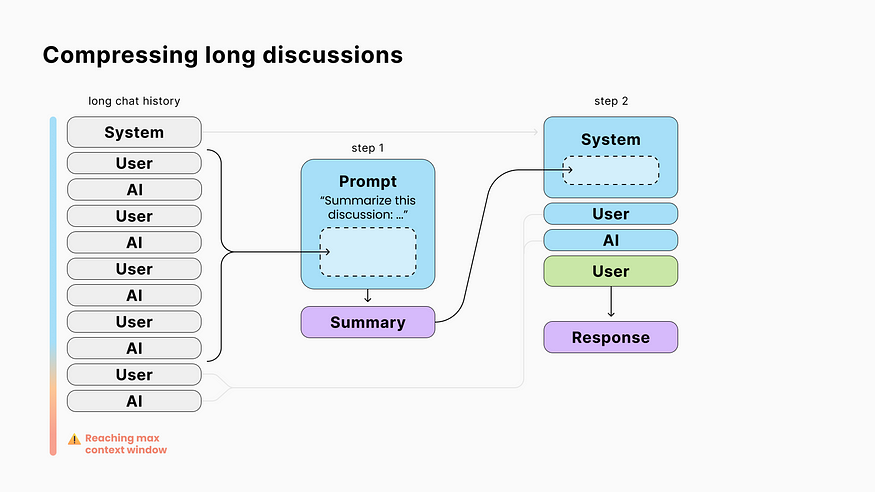
LLMs have a limit on the number of tokens (≈ words) they can read and write in a single request known as the “context window”.
E.g., if a model with a window size of 4096 tokens receives a 3900-tokens prompt, its completion will be limited to 196 tokens.
To avoid hitting this limit and to reduce API costs (since providers charge based on input/output tokens), a solution is to summarize older messages using an intermediate prompt.
🧐 Because this summarization costs you a second LLM request, there is a soft spot to find between doing it too often or not enough.
☝ Also know that larger context windows are rarely the solution. Models with larger context windows are more expensive, larger requests are slower, and too much context can be counter-productive.
You can already read Part 2 of Building LLM-Powered Products, which explores how to give the AI tools it can interact with.
- 登录 发表评论