
category
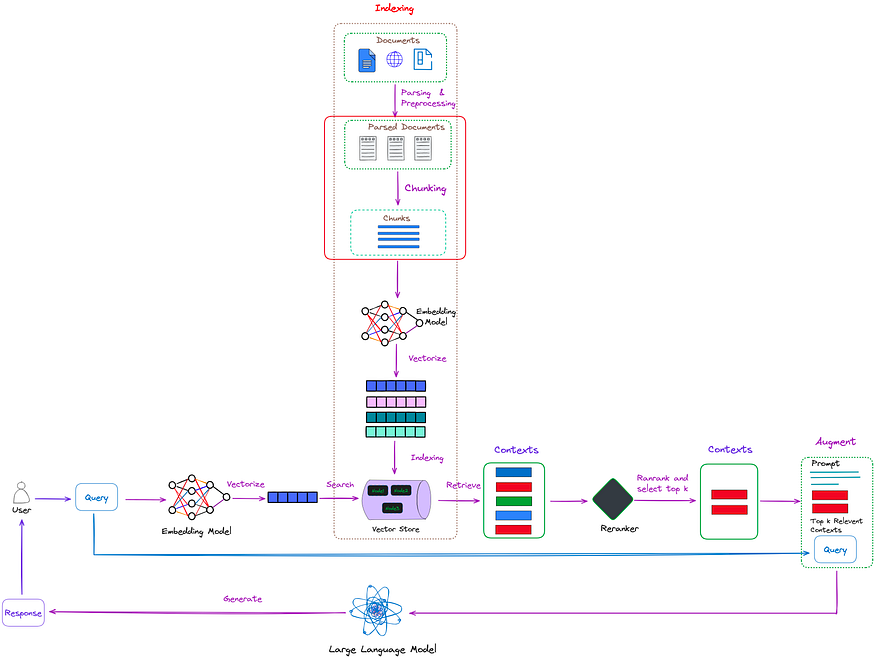
After parsing the document, we can obtain structured or semi-structured data. The main task now is to break them down into smaller chunks to extract detailed features, and then embed these features to represent their semantics. Its position in RAG is shown in Figure 1.
Most commonly used chunking methods are rule-based, employing techniques such as fixed chunk size or overlap of adjacent chunks. For multi-level documents, we can use RecursiveCharacterTextSplitter provided by Langchain. This allows for the definition of multi-level separators.
However, in practical applications, due to the rigid predefined rules (chunk size or size of overlapping parts), rule-based chunking methods can easily lead to problems such as incomplete retrieval contexts or excessive chunk size containing noise.
Therefore, for chunking, the most elegant method is obviously to chunk based on semantics. Semantic chunking aims to ensure that each chunk contains as much semantically independent information as possible.
This article explores the methods of semantic chunking, explaining their principles and applications. We will introduce three types of methods:
- 登录 发表评论