
category
This is Part 1 of my “Understanding Unstructured Data” series. Part 2 focuses on analyzing structured data extracted from unstructured text with a LangChain agent.
Understanding Unstructured Data | Part 1: Extraction

Use case: Extracting Unstructured Competitive Intelligence Data with LLMs
Imagine you are a bakery, and you’ve sent out your confectioner intelligence team to gather competitor data. They report back on what the competition is up to, and they have lots of great ideas that you’d like to apply to your business. However, the data is unstructured! How can you analyze this data to understand what’s being asked for the most and best prioritize the next steps for your business?
Code Available on Github:
Note: the code is split into two files: unstructured_extraction_chain.ipynb and unstructured_pydantic.ipynb depending on the exact tool used.
AI-projects/unstructured_data at main · ingridstevens/AI-projects
AI Projects. Contribute to ingridstevens/AI-projects development by creating an account on GitHub.
To explore this use case, I’ve created a toy data set. Here’s an example datapoint in the dataset:
At Velvet Frosting Cupcakes, our team learned about the unveiling of a seasonal pastry menu that changes monthly. Introducing a rotating seasonal menu at our bakery using the “SeasonalJoy” subscription platform and adding a special touch to our cookies with the “FloralStamp” cookie stamper could keep our offerings fresh and exciting for customers.
Option 1: create_extraction_chain
We can start by looking at the data and in doing so, we can identify a rough schema — or structure — to extract. Using LangChain, we can create an extraction chain.
from langchain.chains import create_extraction_chain
# updated Mar 1 2024 to reflect updated langchain import syntax
from langchain_openai import OpenAI
# Schema
schema = {
"properties": {
"company": {"type": "string"},
"offering": {"type": "string"},
"advantage": {"type": "string"},
"products_and_services": {"type": "string"},
"additional_details": {"type": "string"},
}
}
…next, let’s define a few test inputs:
# Inputs in1 = """Sweet Delights Bakery introduced lavender-infused vanilla cupcakes with a honey buttercream frosting, using the "Frosting-Spreader-3000". This innovation could inspire our next cupcake creation""" in2 = """Whisked Away Cupcakes introduced a dessert subscription service, ensuring regular customers receive fresh batches of various sweets. Exploring a similar subscription model using the "SweetSubs" program could boost customer loyalty.""" in3 = """At Velvet Frosting Cupcakes, our team learned about the unveiling of a seasonal pastry menu that changes monthly. Introducing a rotating seasonal menu at our bakery using the "SeasonalJoy" subscription platform and adding a special touch to our cookies with the "FloralStamp" cookie stamper could keep our offerings fresh and exciting for customers.""" inputs = [in1, in2, in3]
…and create the Chain
# Run chain llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo") chain = create_extraction_chain(schema, llm)
…finally, run the chain over the examples
for input in inputs:
print(chain.run(input))
Now we have structured outputs as Python Lists:
[{'company': 'Sweet Delights Bakery', 'offering': 'lavender-infused vanilla cupcakes', 'advantage': 'inspiring next cupcake creation', 'products_and_services': 'Frosting-Spreader-3000'}]
[{'company': 'Whisked Away Cupcakes', 'offering': 'dessert subscription service', 'advantage': 'ensuring regular customers receive fresh batches of various sweets', 'products_and_services': '', 'additional_details': ''}, {'company': '', 'offering': 'subscription model using the "SweetSubs" program', 'advantage': 'boost customer loyalty', 'products_and_services': '', 'additional_details': ''}]
[{'company': 'Velvet Frosting Cupcakes', 'offering': 'rotating seasonal menu', 'advantage': 'fresh and exciting offerings', 'products_and_services': 'SeasonalJoy subscription platform, FloralStamp cookie stamper'}]
Let’s Update Our Original Data with the Additional Parameters
This is an okay start, and it appears to be functioning. However, the optimal workflow involves importing the CSV containing competitive intelligence, applying it to the extraction chain for parsing and structuring, and seamlessly integrating the parsed information back into the original dataset. The Python code below does just that:
import pandas as pd
from langchain.chains import create_extraction_chain
# updated Mar 1 2024 to reflect updated langchain import syntax
from langchain_openai import ChatOpenAI
# Load in the data.csv (semicolon separated) file
df = pd.read_csv("data.csv", sep=';')
# Define Schema based on your data
schema = {
"properties": {
"company": {"type": "string"},
"offering": {"type": "string"},
"advantage": {"type": "string"},
"products_and_services": {"type": "string"},
"additional_details": {"type": "string"},
}
}
# Create extraction chain
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
chain = create_extraction_chain(schema, llm)
# ----------
# Add the data to a data frame
# ----------
# Extract information and create a DataFrame from the list of dictionaries
extracted_data = df['INTEL'].apply(lambda x: chain.run(x)[0]).apply(pd.Series)
# Replace missing values with NaN
extracted_data.replace('', np.nan, inplace=True)
# Concatenate the extracted_data DataFrame with the original df
df = pd.concat([df, extracted_data], axis=1)
# display the data frame
df.head()
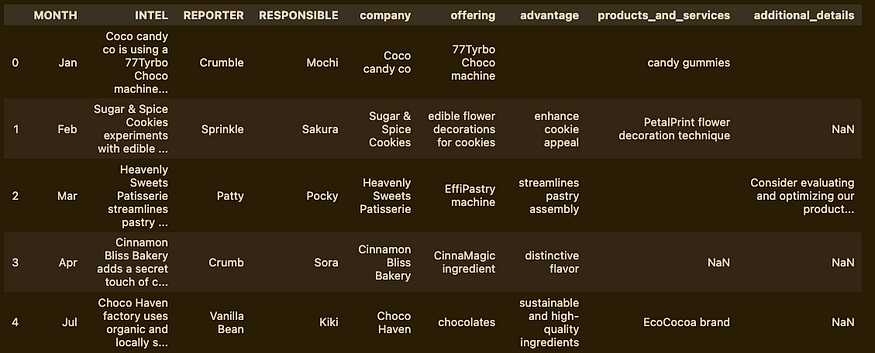
This run took about 15 seconds, and it hasn’t found all the information we’re requesting.
Let’s try a different method instead.
Option 2: Pydantic
In the code that follows, Pydantic is being used to define data models that represent the structure of the competitive intelligence information. Pydantic is a data validation and parsing library for Python that allows you to define simple or complex data structures using Python data types. In this case, we using Pydantic models (Competitor and Company) to define the structure of the competitive intelligence data.
import pandas as pd
from typing import Optional, Sequence
# updated Mar 1 2024 to reflect updated langchain import syntax
from langchain_openai import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from pydantic import BaseModel
# Load data from CSV
df = pd.read_csv("data.csv", sep=';')
# Pydantic models for competitive intelligence
class Competitor(BaseModel):
company: str
offering: str
advantage: str
products_and_services: str
additional_details: str
class Company(BaseModel):
"""Identifying information about all competitive intelligence in a text."""
company: Sequence[Competitor]
# Set up a Pydantic parser and prompt template
parser = PydanticOutputParser(pydantic_object=Company)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Function to process each row and extract information
def process_row(row):
_input = prompt.format_prompt(query=row['INTEL'])
model = OpenAI(temperature=0)
output = model(_input.to_string())
result = parser.parse(output)
# Convert Pydantic result to a dictionary
competitor_data = result.model_dump()
# Flatten the nested structure for DataFrame creation
flat_data = {'INTEL': [], 'company': [], 'offering': [], 'advantage': [], 'products_and_services': [], 'additional_details': []}
for entry in competitor_data['company']:
flat_data['INTEL'].append(row['INTEL'])
flat_data['company'].append(entry['company'])
flat_data['offering'].append(entry['offering'])
flat_data['advantage'].append(entry['advantage'])
flat_data['products_and_services'].append(entry['products_and_services'])
flat_data['additional_details'].append(entry['additional_details'])
# Create a DataFrame from the flattened data
df_cake = pd.DataFrame(flat_data)
return df_cake
# Apply the function to each row and concatenate the results
intel_df = pd.concat(df.apply(process_row, axis=1).tolist(), ignore_index=True)
# Display the resulting DataFrame
intel_df.head()
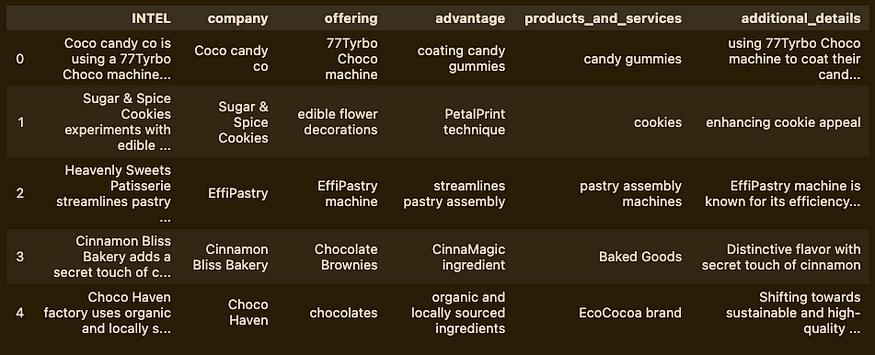
That was really quick! And it found details for all of the entries, unlike the create_extraction_chain attempt.
Concluding Thoughts
I found that PydanticOutputParser was faster and more reliable. Each run took about 1 sec and 400 tokens to run. Whereas the create_extraction_chain took about 2.5sec and 250 tokens to run.
We’ve managed to extract some structured data out of unstructured text! That’s great! The next step is to analyze that data. Part 2 focuses on analyzing structured data extracted from unstructured text with a LangChain agent.

- 登录 发表评论