
category
Prologue
As the wave of interest in Large Language Models (LLMs) surges, many developers and organisations are busy building applications harnessing their power. However, when the pre-trained LLMs out of the box don’t perform as expected or hoped, the question on how to improve the performance of the LLM application. And eventually we get to the point of where we ask ourselves: Should we use Retrieval-Augmented Generation (RAG) or model finetuning to improve the results?
Before diving deeper, let’s demystify these two methods:
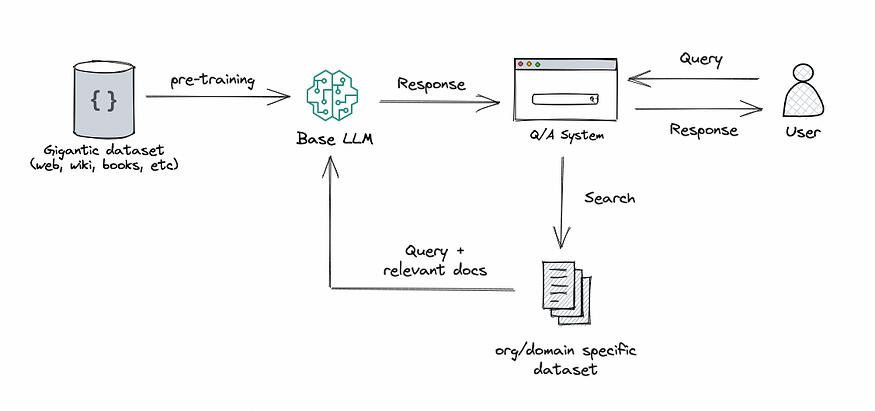
RAG: This approach integrates the power of retrieval (or searching) into LLM text generation. It combines a retriever system, which fetches relevant document snippets from a large corpus, and an LLM, which produces answers using the information from those snippets. In essence, RAG helps the model to “look up” external information to improve its responses.
- 登录 发表评论