
介绍
LlamaIndex(GPT Index)提供了一个将大型语言模型(LLM)与外部数据连接起来的接口。LlamaIndex提供了各种数据结构来索引数据,如列表索引、向量索引、关键字索引和树索引。它提供了高级API和低级API——高级API允许您仅用五行代码构建问题解答(QA)系统,而低级API允许您定制检索和合成的各个方面。
然而,将这些系统投入生产需要仔细评估整个系统的性能,即给定输入的输出质量。检索增强生成的评估可能具有挑战性,因为用户需要针对给定的上下文提出相关问题的数据集。为了克服这些障碍,LlamaIndex提供了问题生成和无标签评估模块。
在本博客中,我们将讨论使用问题生成和评估模块的三步评估过程:
- 从文档生成问题
- 使用LlamaIndex QueryEngine抽象生成问题的答案/源节点,该抽象管理LLM和数据索引之间的交互。
- 评估问题(查询)、答案和源节点是否匹配/内联
1.问题生成
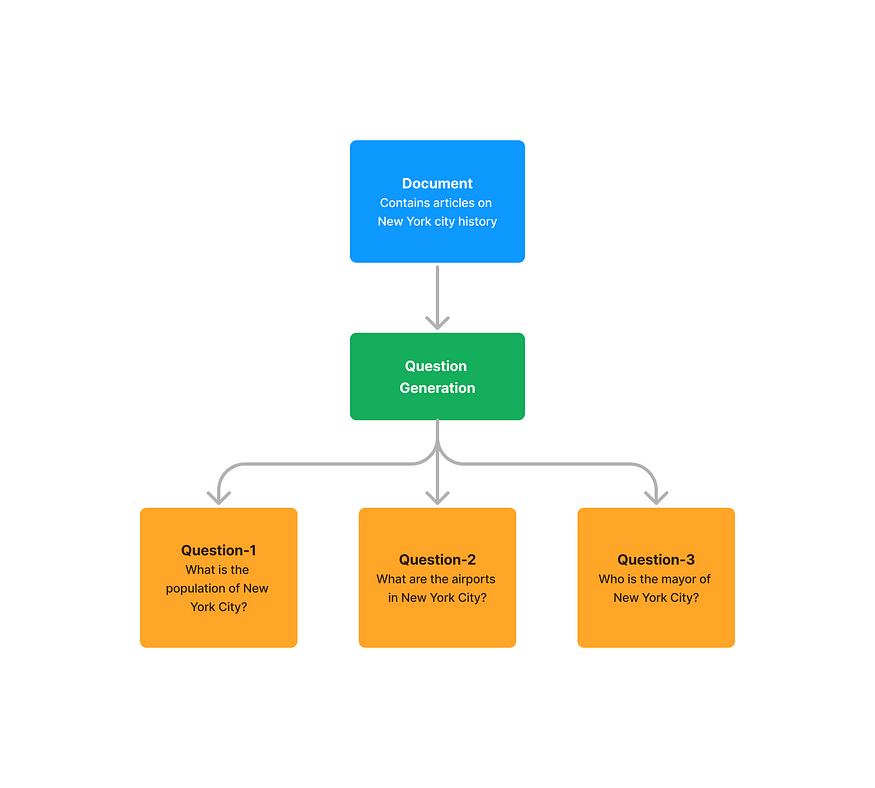
应该注意的是,这种方法不需要地面实况标签。问题生成的目的是生成上下文输入的初始数据集,该数据集可用于评估问答系统。
LlamaIndex提供了DataGenerator类,该类使用ListIndex从给定文档中生成问题。默认情况下,它使用OpenAI ChatGPT(get-3.5-turbo)生成问题。
from llama_index.evaluation import DatasetGenerator
from llama_index import SimpleDirectoryReader
# Load documents
reader = SimpleDirectoryReader("./data")
documents = reader.load_data()
# Generate Question
data_generator = DatasetGenerator.from_documents(documents)
question = data_generator.generate_questions_from_nodes()
2.生成答案/源节点(上下文)
使用List Index,我们为响应对象中生成的问题生成答案和源节点。
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader, load_index_from_storage, StorageContext
# load documents
documents = SimpleDirectoryReader('./data').load_data()
# Create Index
index = GPTVectorStoreIndex.from_documents(documents)
# save index to disk
index.set_index_id("vector_index")
index.storage_context.persist('storage')
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir='storage')
# load index
index = load_index_from_storage(storage_context, index_id="vector_index")
# Query the index
query_engine = index.as_query_engine(similarity_top_k=3)
response = query_engine.query(<Query>)
# Response object has both response and source nodes.
3.评估
评估模块可用于回答以下三个问题:
- 生成的响应和源节点(上下文)是否匹配?-响应+源节点(上下文)
- 是否生成响应、源节点(上下文)和查询匹配?-查询+响应+源节点(上下文)
- 检索到的源节点中的哪些源节点用于生成响应?-查询+响应+单个源节点(上下文)
评估可以通过查询、上下文和响应的某种组合来完成,并将它们与LLM调用相结合。
响应+源节点(上下文)
此函数回答了以下问题:生成的响应和源节点(上下文)是否匹配?
给定查询的响应对象返回响应和生成响应的源节点(上下文)。我们现在可以根据检索到的源来评估响应,而无需考虑查询!这允许您测量幻觉-如果响应与检索到的来源不匹配,这意味着模型可能“产生幻觉”了一个答案,因为它没有将答案植根于提示中提供给它的上下文中。
结果是一个二进制响应——“是/否”。
- 是-响应节点和源节点(上下文)匹配。
- 否-响应节点和源节点(上下文)不匹配。
from llama_index.evaluation import ResponseEvaluator # build service context llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-4")) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor) # Build index and get response object ... # define evaluator evaluator = ResponseEvaluator(service_context=service_context) # evaluate using the response object eval_result = evaluator.evaluate(response)

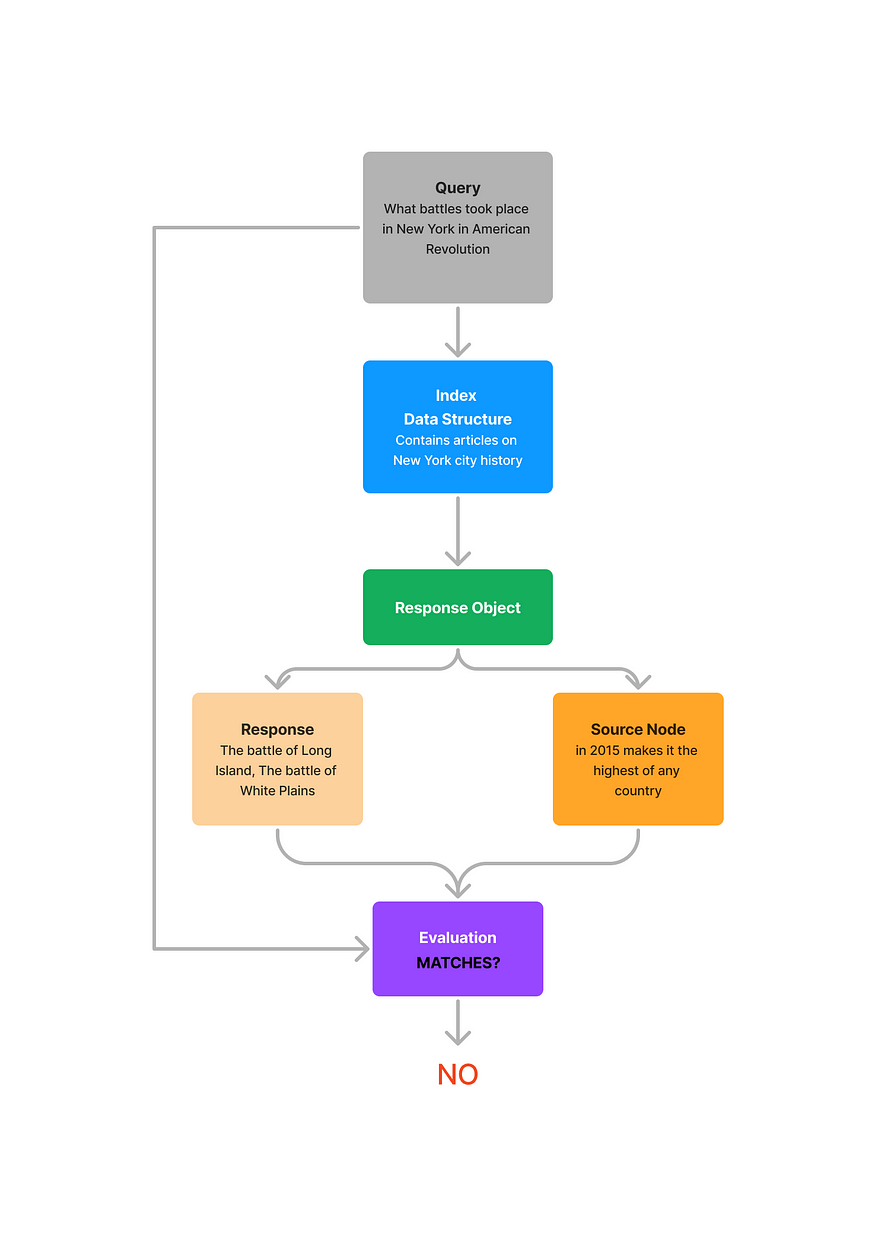
查询+响应+源节点(上下文)
此函数回答了以下问题:是否生成响应、源节点(上下文)和查询匹配?
通常使用“响应+源节点(上下文)”方法,生成的响应与源节点一致,但可能不是查询的答案。因此,将查询与响应和源节点一起考虑是进行更准确分析的好方法。
目标是确定响应+源上下文是否回答了查询。结果是一个二进制响应——“是/否”。
- 是-查询、响应和源节点(上下文)匹配。
- 否-查询、响应和源节点(上下文)不匹配。
from llama_index.evaluation import QueryResponseEvaluator # build service context llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-4")) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor) # Build index and get response object ... # define evaluator evaluator = QueryResponseEvaluator(service_context=service_context) # evaluate using the response object eval_result = evaluator.evaluate(query, response)
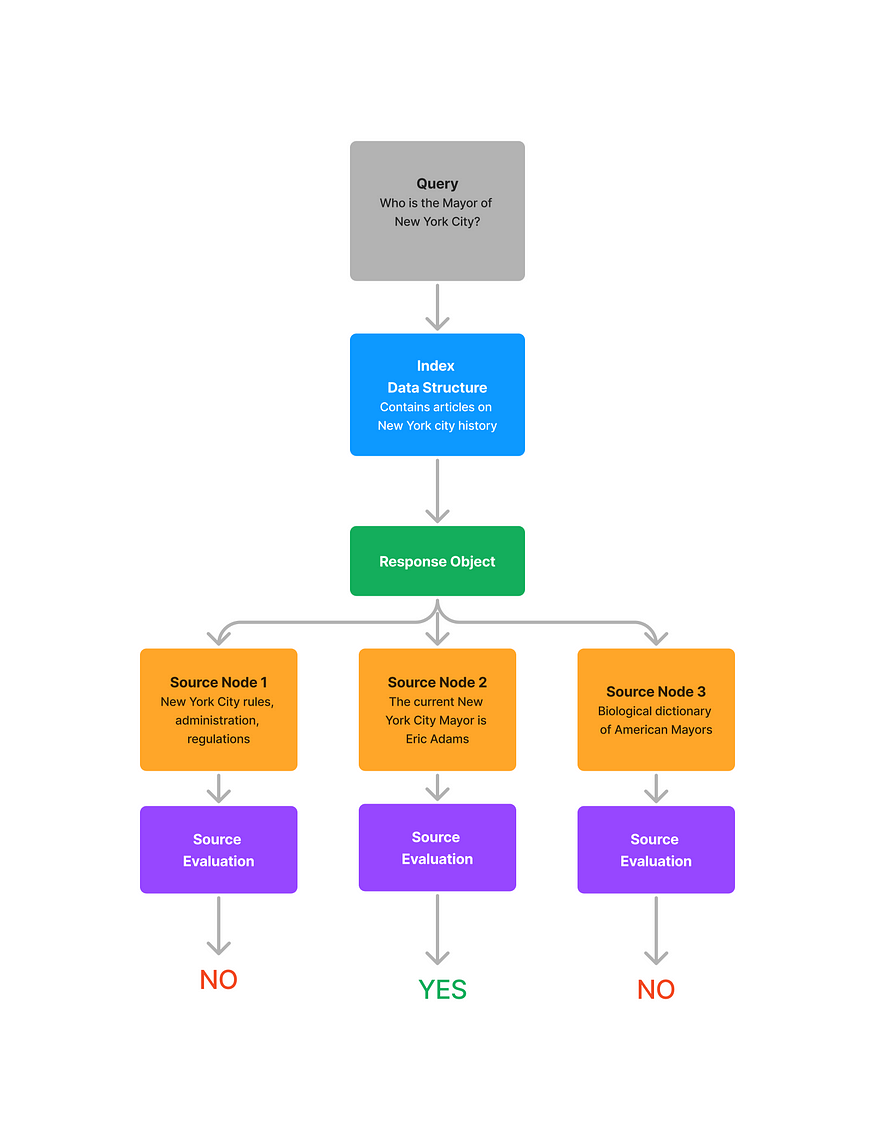
查询+响应+单个源节点(上下文)
此函数回答以下问题:检索到的源节点中的哪些源节点用于生成响应?
通常在现实世界中,源节点可以是来自不同文档的节点。在这些情况下,重要的是要了解哪些源节点是相关的,并向用户显示这些文档。这种评估模式将查看每个源节点,看看每个源节点是否包含查询的答案。
from llama_index.evaluation import QueryResponseEvaluator # build service context llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-4")) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor) # build index and get response object ... # define evaluator evaluator = QueryResponseEvaluator(service_context=service_context) # evaluate using the response object eval_result = evaluator.evaluate_source_nodes(response)
谷歌Colab笔记本电脑,用于使用LlamaIndex评估QA系统-
结论
LlamaIndex为构建和评估QA系统提供了一个全面的解决方案,而无需地面实况标签。通过使用问题生成和评估模块,您可以确保您的系统准确可靠,使其适合生产环境。
- 登录 发表评论