
ChatGPT能够在几秒钟内就任何主题生成连贯全面的文章,这使它成为改变游戏规则的信息资源,也是教育工作者的克星。OpenAI的对话式大型语言模型在发布后的几周内积累了数百万每日用户,但也被美国、澳大利亚、法国和印度的学区禁止。
虽然强大的大型语言模型(LLM),如ChatGPT(OpenAI,2022)、PaLM(Chowdhery et al.,2022)和GPT-3(Brown et al.,2020),有无数有益的应用,但它们也可以用来在家庭作业中作弊,或写令人信服但不准确的新闻文章。此外,他们经常产生虚假信息。因此,区分机器从人类书写的文本中生成的任务在许多领域变得至关重要。但随着LLM输出变得越来越流畅和人性化,这项任务变得越来越困难。
斯坦福大学的一个研究团队在新论文《DetectGPT:使用概率曲率的零样本机器生成文本检测》中解决了这个问题,提出了DetectGPS,一种新的零样本机器生成文本的检测方法,使用概率曲率来预测候选通道是否由特定LLM生成。

该团队将其研究的主要贡献总结如下:
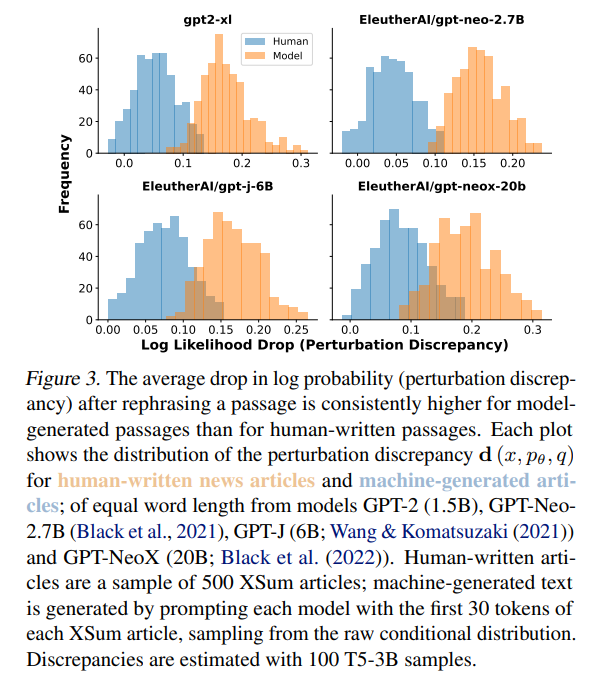
模型对数概率函数的曲率在模型样本中往往比在人类文本中更负,这一假设的识别和实证验证。
DetectGPT是一种受这一假设启发的实用算法,它近似于对数概率函数的Hessian的轨迹来检测模型的样本。
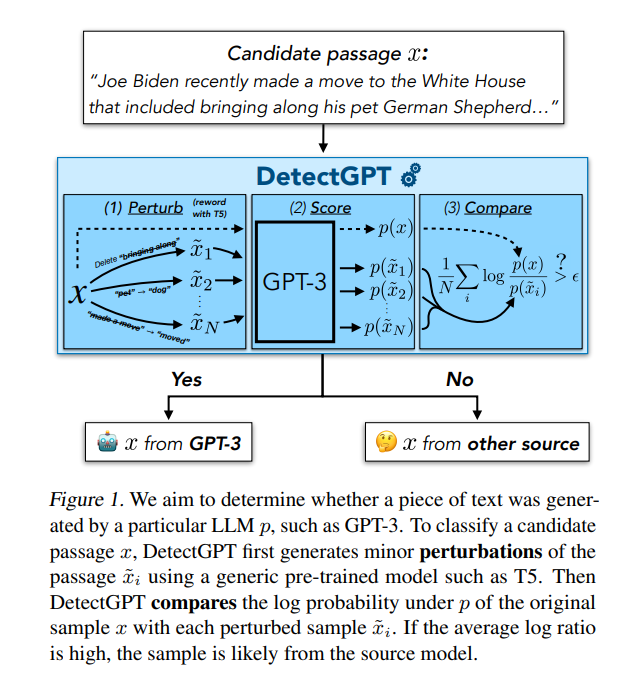
这项工作的重点是零样本机器生成的文本检测任务:给定一个样本文本(“候选段落”),模型学习预测它是否由特定的源LLM生成。
在零样本设置下工作,DetectGPT不需要人为编写或生成样本进行培训;相反,它利用通用的预训练掩模填充模型来生成候选通道的微小扰动。DetectGPT然后基于这样的假设进行操作,即来自特定源模型的样本通常位于该源模型的对数概率函数的负曲率区域中。
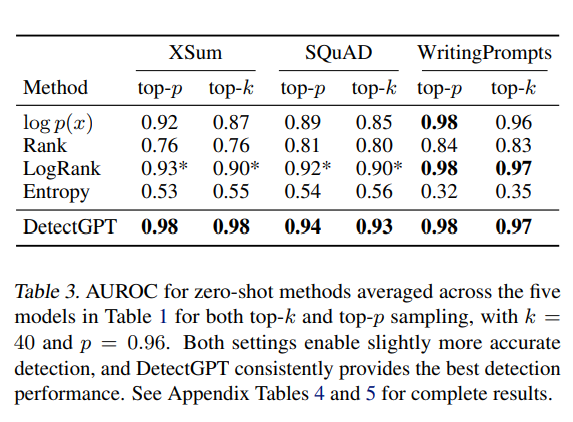
为了评估DetectGPT的有效性,该团队将其与现有的零样本方法(如秩、对数秩和熵)进行了比较。他们使用XSum数据集(Narayan等人,2018)进行假新闻检测,并使用SQuAD上下文中的维基百科段落(Rajpurkar等人,2016)和Reddit WritingPrompts(Fan等人,2018年)数据集进行学术和创意写作检测。在实验中,DetectGPT在XSum上的表现优于最强的零样本基线,超过0.1 AUROC(接收器操作特征下的面积,一种分类性能指标),并在SQuAD Wikipedia上下文上显示出0.05 AUROC的改进。DetectGPT还实现了与在数百万样本上训练的监督检测模型相比具有竞争力的性能。
就在这篇论文发表五天后,OpenAI发布了自己的AI文本分类器检测工具。人们对这些工具的反应褒贬不一,加州大学伯克利分校学生Charis Zhang在推特上总结了怀疑论者的立场:“曾经有一段时间,GPT生成的文本很容易被检测到,但现在基本上不是这样。此外,人们不会在不更改GPT的情况下直接从GPT复制和粘贴,这会使任何人工智能检测模型完全失效。”
arXiv上论文《DetectGPT:使用概率曲率的零样本机器生成文本检测》。
- 登录 发表评论