
【隐私保护】Presidio简化了PII匿名化
匿名化的背景和如何构建匿名器
随着GDPR在欧洲实施后的各种法规,正确处理敏感信息,特别是个人身份信息(PII)成为许多公司的要求。在本文中,我们将讨论什么是PII,以及如何在非结构化数据(尤其是文本)中匿名化PII。我们还将演示使用Microsoft Presidio的文本匿名器的示例实现,这是一个提供快速PII识别和匿名模块的开源库。本文分为以下几个部分:
- 背景:隐私和匿名
- 现有的匿名技术
- 使用Microsoft Presidio自定义PII匿名器
- 结论、链接和参考文献
跳到任何你觉得最有趣的部分!
背景
早在19世纪50年代,数据保护和隐私保护技术就已被研究和应用,当时美国人口普查局开始从公开的美国公民人口普查数据中删除个人数据。自从早期使用诸如添加随机噪声或聚合之类的简单技术以来,已经提出并改进了各种模型。隐私权是一项基本人权。根据字典的定义,它是
个人或群体将自己或关于自己的信息隐藏起来,从而有选择地表达自己的能力。
【自然语言处理】用Python从文本中删除个人信息-第二部分
Python中隐私过滤器的实现,该过滤器通过命名实体识别(NER)删除个人身份信息(PII)
这是我上一篇关于从文本中删除个人信息的文章的后续内容。
GDPR是欧盟制定的《通用数据保护条例》。其目的是保护所有欧洲居民的数据。保护数据也是开发人员的内在价值。通过控制对列和行的访问,保护行/列数据结构中的数据相对容易。但是免费文本呢?
在我上一篇文章中,我描述了一个基于正则表达式用法和禁止词列表的解决方案。在本文中,我们添加了一个基于命名实体识别(NER)的实现。完整的实现可以在github PrivacyFilter项目中找到。
什么是命名实体识别?
根据维基百科,NER是:
命名实体识别(NER)(也称为(命名)实体识别、实体分块和实体提取)是信息提取的一个子任务,旨在定位非结构化文本中提到的命名实体,并将其分类为预定义的类别,如人名、组织、位置、医疗代码、时间表达式、数量、货币值、百分比等。
【隐私保护】Presidio支持的PII实体
Presidio包含PII实体的预定义识别器。本页介绍了Presidio可以检测的不同实体,以及Presidio用于检测这些实体的方法。
此外,Presidio允许您添加自定义实体识别器。有关详细信息,请参阅添加新识别器文档。
【自然语言处理】第3部分:识别文本中的个人身份信息
在文本文档中查找个人身份信息(PII)可能很有用,原因有几个,但我多次遇到的一个用例是帮助匿名文本,以便:
- 与第三方共享数据
- 遵守GDPR等法规要求
- 将PII替换为模拟数据,用作机器学习和其他探索性分析的训练数据
我将尝试自动化查找PII的过程,在本系列文章中,我们将探索一些流行的开源工具和技术,以便在我们自己的数据中识别不同类型的PII。
到目前为止,我们已经找到了查找人名、电子邮件地址、电话号码和信用卡号码的方法。让我们看看我们还能找到哪些其他类型的PII。
介绍Hugging Face
Hugging Face是一个流行的Python库,包含预先训练的人工智能模型,可用于各种自然语言处理(NLP)任务,包括命名实体识别(NER)。正如我们在前几篇文章中所讨论的,NER是一种非常有用的检测文本中PII的技术。
Python示例
让我们看看我们将如何使用拥抱脸。
先决条件:
【自然语言处理】第2部分:识别文本中的个人身份信息
在文本文档中查找个人身份信息(PII)可能很有用,原因有几个,但我多次遇到的一个用例是帮助匿名文本,以便:
- 与第三方共享数据
- 遵守GDPR等法规要求
- 将PII替换为模拟数据,用作机器学习和其他探索性分析的训练数据
我将尝试自动化查找PII的过程,在本系列文章中,我们将探索一些流行的开源工具和技术,以便在我们自己的数据中识别不同类型的PII。
在第一部分中,我们找到了一种在文本中查找人名的方法,让我们看看我们还可以找到其他类型的PII。
介绍Duckling
Duckling是一个Haskell库,由Facebook开源,用于将文本解析为结构化数据。Duckling可以帮助我们在文本中找到不同类型的信息,包括信用卡号码、电子邮件地址和电话号码。
现在别担心,如果你不是了解Haskell的三个人之一,我们可以将Duckling与任何编程语言一起使用。
Python示例
让我们看看我们将如何用一种不需要关于副作用的害处的演讲的语言来使用Duckling。
【自然语言处理】第1部分:识别文本中的个人身份信息
在文本文档中查找个人身份信息(PII)可能很有用,原因有几个,但我多次遇到的一个用例是帮助匿名化文本数据,以便:
- 与第三方共享数据
- 遵守GDPR等法规要求
- 用作机器学习和其他探索性分析的训练数据
- 你是Facebook,你终于想做正确的事情了(/S)
我将尝试自动化查找PII的过程,在本系列文章中,我们将探索一些流行的开源工具和技术,以便在我们自己的数据中识别不同类型的PII。
介绍spaCy
命名实体识别(NER)试图识别文本数据中有意义的单词,如人名、地点、日期等。有几个开源工具使用NER来帮助识别有意义的词,我们将在本文中重点介绍的一个非常受欢迎的项目叫做spaCy。
spaCy是一个用于自然语言处理的免费开源python库,具有NER功能,可以帮助我们识别人名、地点和其他潜在有用的信息。
Python示例
先决条件:
【LLM 】7个基本的NLP模型,为ML应用程序赋能
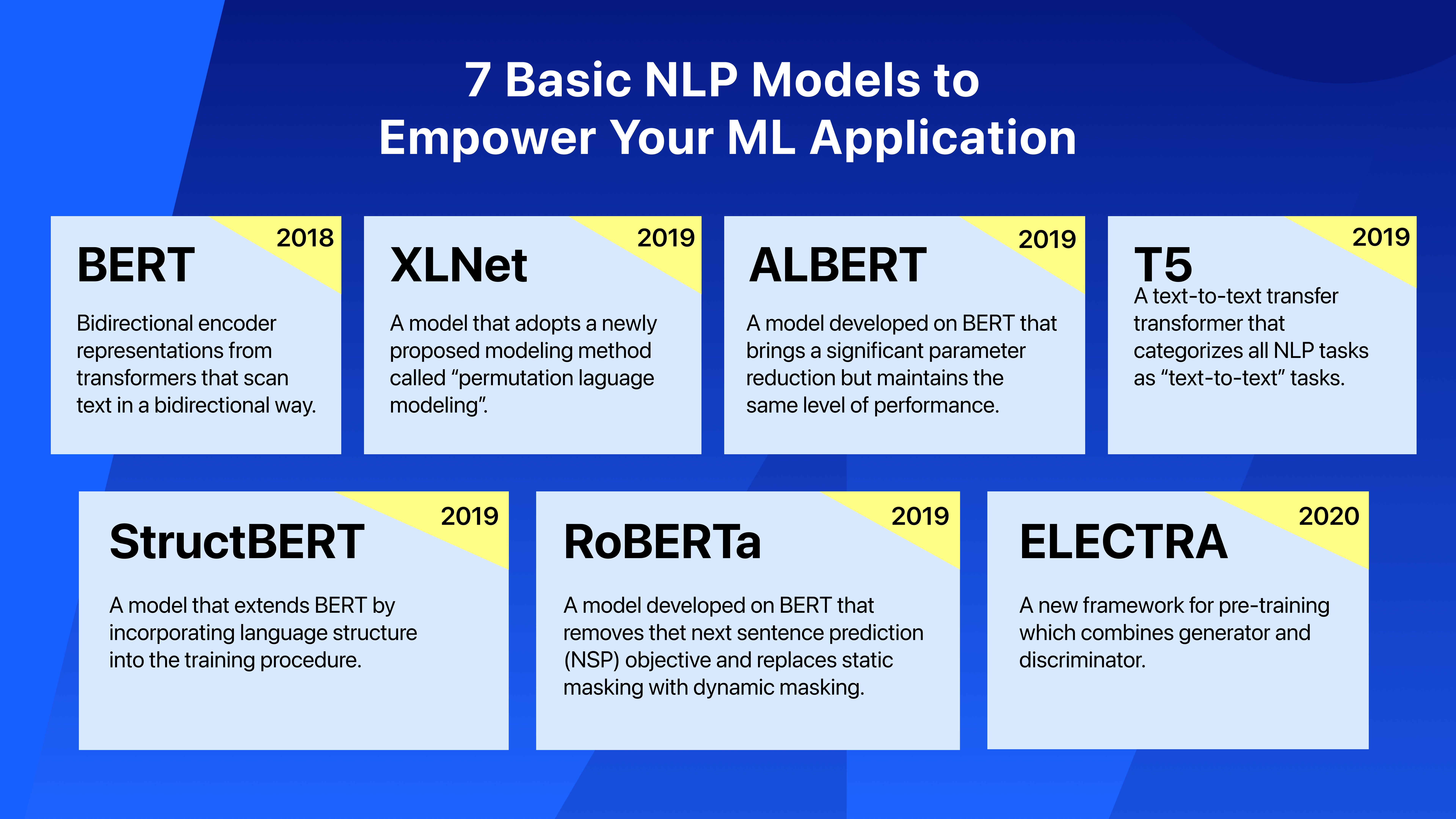
在上一篇文章中,我们已经解释了什么是NLP及其在现实世界中的应用。在这篇文章中,我们将继续介绍NLP应用程序中使用的一些主要深度学习模型。
【DetectGPT】斯坦福大学的DetectGPT采用基于曲率的LLM生成文本检测方法
ChatGPT能够在几秒钟内就任何主题生成连贯全面的文章,这使它成为改变游戏规则的信息资源,也是教育工作者的克星。OpenAI的对话式大型语言模型在发布后的几周内积累了数百万每日用户,但也被美国、澳大利亚、法国和印度的学区禁止。
虽然强大的大型语言模型(LLM),如ChatGPT(OpenAI,2022)、PaLM(Chowdhery et al.,2022)和GPT-3(Brown et al.,2020),有无数有益的应用,但它们也可以用来在家庭作业中作弊,或写令人信服但不准确的新闻文章。此外,他们经常产生虚假信息。因此,区分机器从人类书写的文本中生成的任务在许多领域变得至关重要。但随着LLM输出变得越来越流畅和人性化,这项任务变得越来越困难。
斯坦福大学的一个研究团队在新论文《DetectGPT:使用概率曲率的零样本机器生成文本检测》中解决了这个问题,提出了DetectGPS,一种新的零样本机器生成文本的检测方法,使用概率曲率来预测候选通道是否由特定LLM生成。

该团队将其研究的主要贡献总结如下: